
4月8日,据消息,深度求索(DeepSeek)与清华大学携手合作,共同推出了全新的AI对齐技术——SPCT(自我原则点评调优)。这项技术打破了传统模式中对海量训练数据的依赖,转而通过在推理阶段进行动态优化,以此来提升输出质量。
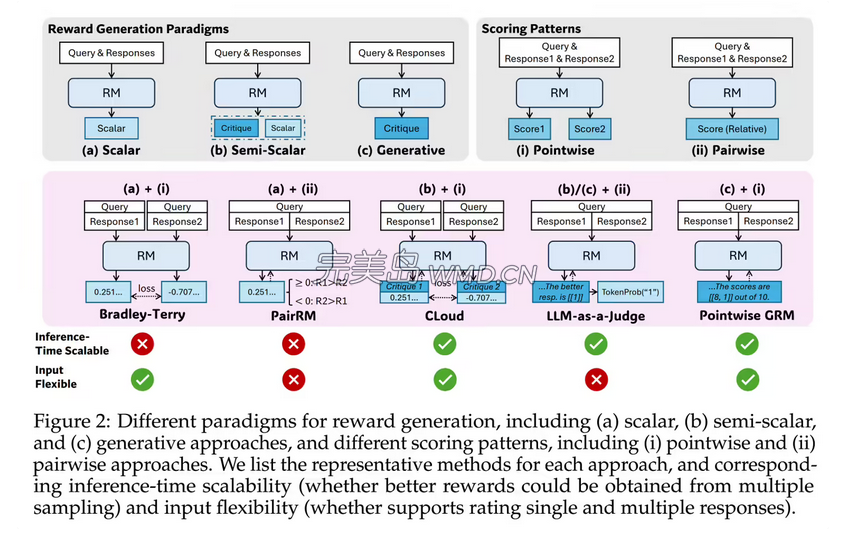
据研究团队于4月4日发表的论文显示,SPCT技术采用了一种独特的递归架构,即“原则合成 - 响应生成 - 批判过滤 - 原则优化”。借助这一架构,模型能够在推理过程中自动对输出内容进行动态修正。
SPCT方法主要由两个阶段构成。首先是拒绝式微调阶段,此阶段作为冷启动,其主要作用是让GRM能够适应不同的输入类型,并以正确的格式生成原则与点评内容。其次是基于规则的在线强化学习阶段,在该阶段中,采用基于规则的结果奖励机制,以此激励GRM生成更为优质的原则与点评内容,进而提升推理阶段的可扩展性。
在相关测试中,拥有270亿参数的DeepSeek - GRM模型表现亮眼。在每查询32次采样的推理计算条件下,该模型达到了671B规模模型的性能水平。其硬件感知设计采用了混合专家系统(MoE),可支持128k token上下文窗口,单查询延迟仅为1.4秒。
| 模型 | 规模 | MT-Bench | 预估训练成本 |
|---|---|---|---|
| DeepSeek-GRM | 27B | 8.35 | $12,000 |
| Nemotron-4 | 340B | 8.41 | $1.2 million |
| GPT-4o | 1.8T | 8.72 | $6.3 million |
报告明确指出,SPCT技术能够显著降低高性能模型的部署门槛。以DeepSeek - GRM模型为例,其训练成本约为1.2万美元(完美岛ai:按照现汇率约合87871元人民币),在MT - Bench测试中的得分为8.35。
与之形成对比的是,340B的Nemotron - 4想要获得8.41分的成绩,需要花费120万美元。OpenAI的1.8T参数GPT - 4o虽然得到了8.72分,但成本却高达630万美元(按现汇率约合4613.2万元人民币),而DeepSeek - GRM模型的成本仅为其525分之一。此外,该技术还减少了90%的人工标注需求,能耗较DPO降低了73%,为实时机器人控制等动态场景带来了新的可能性。