谷歌终于上线的Gemini 2.0的原生多模态图片输出功能,标志着其在人工智能领域的又一重大突破。文字就能编辑和生成图片,而且图片质量相当高!
- 功能概述
- Gemini 2.0 Flash支持原生图像生成,能够同时理解文本、图像等多模态数据作为输入,并输出文本、语音和图像等多种模态的数据。用户可以通过自然语言提示,让模型生成与之相关的图像。例如,用户可以讲述一个故事,模型会用图片进行说明,并保持角色和场景的一致性;也可以进行对话式图像编辑,通过多轮自然语言对话来优化图像,或共同探索不同的创意。
- 技术优势
- 强大的多模态理解能力:Gemini 2.0 Flash能够真正理解多模态的信息,包括文字、图像以及二者之间的联系。它可以从URL解析YouTube视频并给出内容摘要,还能根据自然语言提示生成高度一致且符合逻辑的图像,如生成30岁中年女性的不同角度照片等。
- 结合世界知识与推理能力:该模型利用世界知识和增强推理能力来生成更准确、更符合上下文的图像。比如在为食谱配图时,能够生成逼真的详细图像;在渲染长文本序列方面也表现出色,适合创建广告、社交媒体帖子、邀请函等内容,内部基准测试表明其在这方面比领先的竞争模型表现更强。
- 高效的性能表现:在关键基准测试中,Gemini 2.0 Flash的性能超越前代产品Gemini 1.5 Pro,速度达到Gemini 1.5 Pro的两倍,显著降低了延迟,这对于实时交互应用至关重要。
- 应用场景
- 内容创作领域:创作者可以利用该功能轻松制作出图文并茂的内容,如绘本、漫画、故事脚本等,大大提高创作效率和质量。比如在漫画创作中,只需简单的提示就能完成素描转换为线稿、填充基础色、添加阴影等操作,并且可以保持输出图像与原图的高度一致性。
- 设计与广告行业:设计师和广告人员可以快速生成符合需求的广告海报、宣传图片等,还可以根据客户的反馈及时进行修改和优化,节省时间和成本。
- 教育与培训领域:教师可以生成与教学内容相关的图像辅助教学,帮助学生更好地理解和掌握知识;学生也可以通过该功能制作学习笔记、演示文稿等。
总的来说,谷歌Gemini 2.0原生多模态图片输出功能凭借其强大的技术实力和广泛的应用前景,为用户带来了更加智能、高效和便捷的体验,有望在多个领域推动创新和发展。
依旧可以白嫖,下面是使用方式和一些案例:

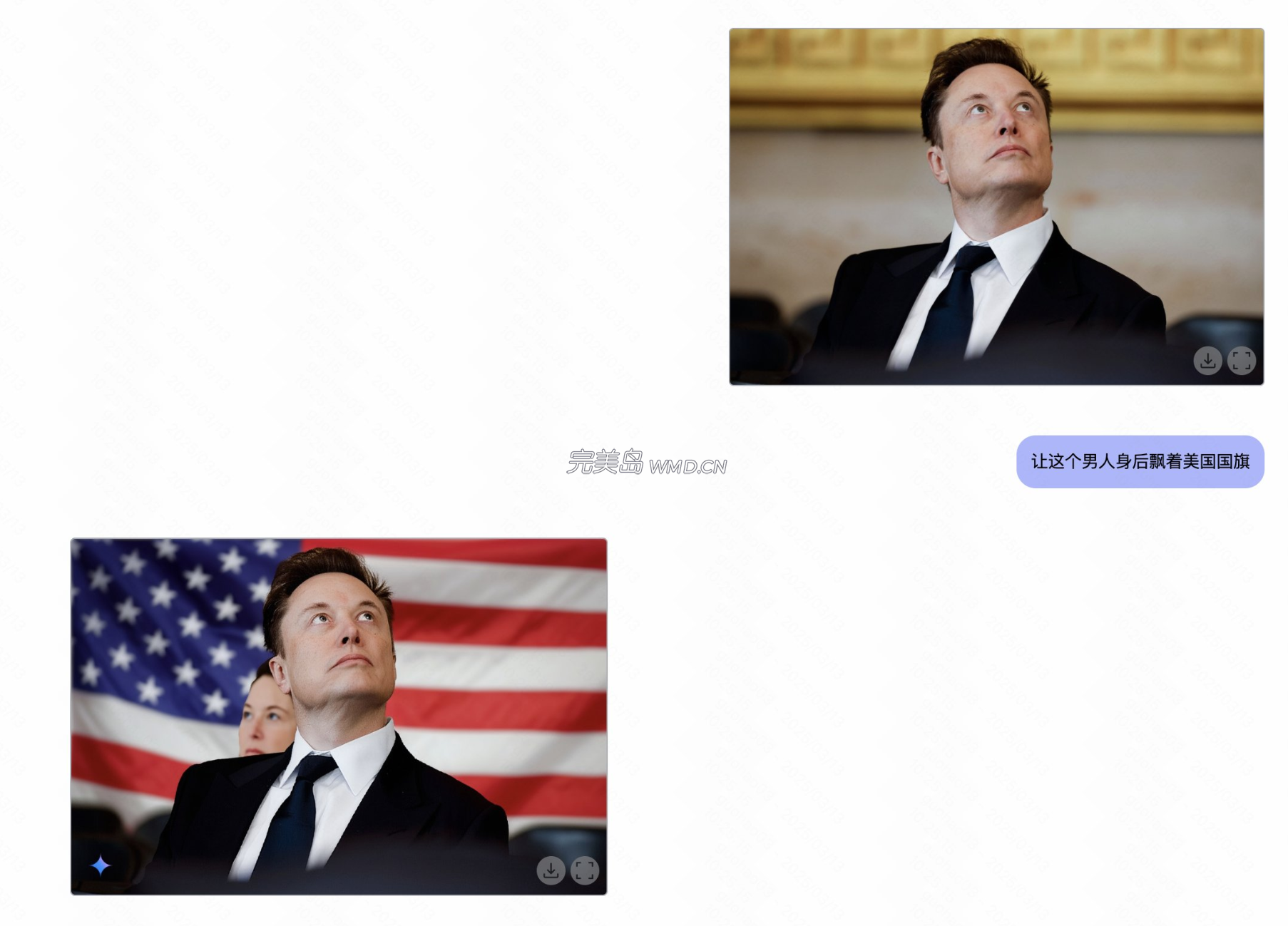
使用方式: 打开 AI Studio 右侧将模型切换为 Gemini 2.0 Flash Experimental 直接自然语言跟模型沟通就行 :